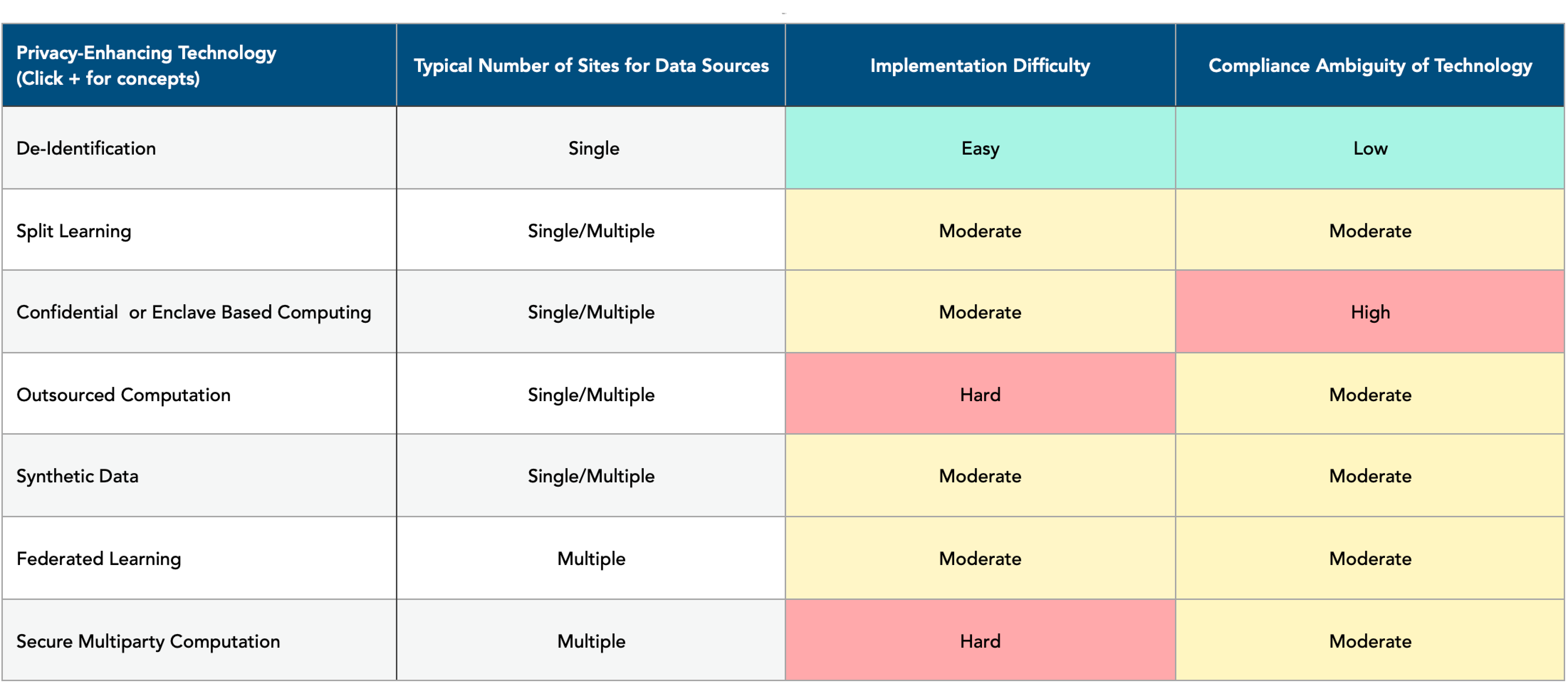
De-Identification
Split Learning

Confidential or Enclave Based Computing

Outsourced Computation

Synthetic Data

Federated Learning

Secure Multiparty Computation
